Explainable Human-Robot Interaction Learning with Video Augmentation Techniques
< Projects June 2022 ~ Present Personal Robots Group, MIT Media Lab
Multi-Party Human-Robot Conversation Interactions
Affect understanding capability is essential for social robots to autonomously interact with a group of users in an intuitive and reciprocal way. In this work, we use a dataset (namely Triadic) of parent-child dyads reading storybooks together with a social robot at home. First, we train 1) RGB frame- and 2) skeleton- based joint engagement recognition models with four video augmentation techniques (General Aug, DeepFake, CutOut, and Mixed) applied datasets to improve joint engagement classification performance. Second, we demonstrate experimental results on the use of trained models in the robot-parent-child interaction context. Third, we introduce a behavior-based metric for evaluating the learned representation of the models to investigate the model interpretability when recognizing parent-child joint engagement. This work serves as the first step toward fully unlocking the potential of end-to-end video understanding models pre-trained on large public datasets augmented with feature aplified augmentation and visualization techniques for affect recognition in the multi-person human-robot interaction in the wild.
Research Topics
Overview
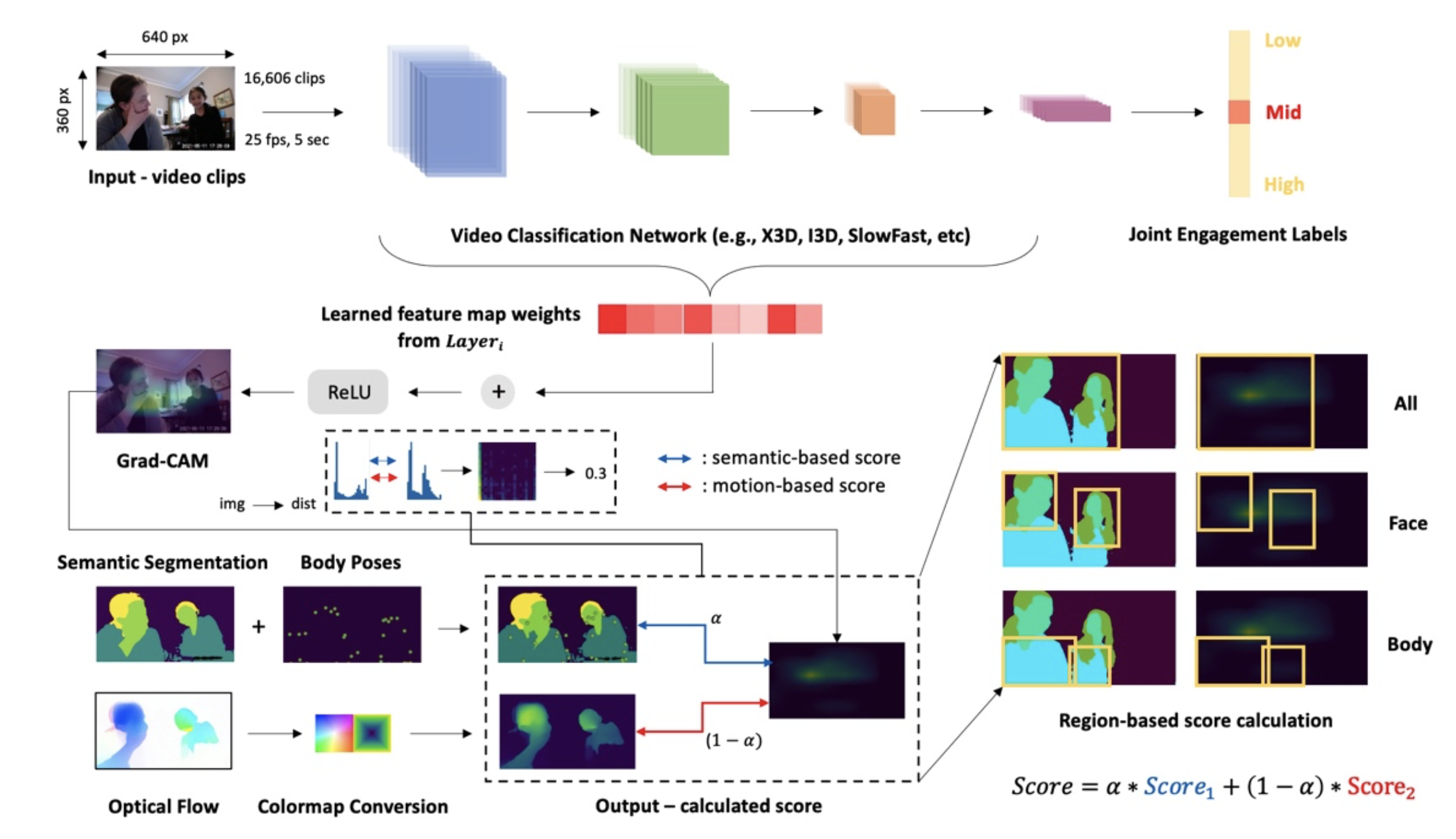
We propose a framework for evaluating the learned representation (Grad-CAM) with modified Optical Flow and skeleton information combined Semantic Segmentation as two references. With the fine-tuned models (on publicly available dataset such as Kinetics-400), we generate Grad-CAM inference for each video clip and evaluate its quality by calculating the score. We calculate the evaluation score based on two sub-scores (1) semantic-based and 2) motion-based) which are obtained by applying mutual information and cross-entropy.
Dataset
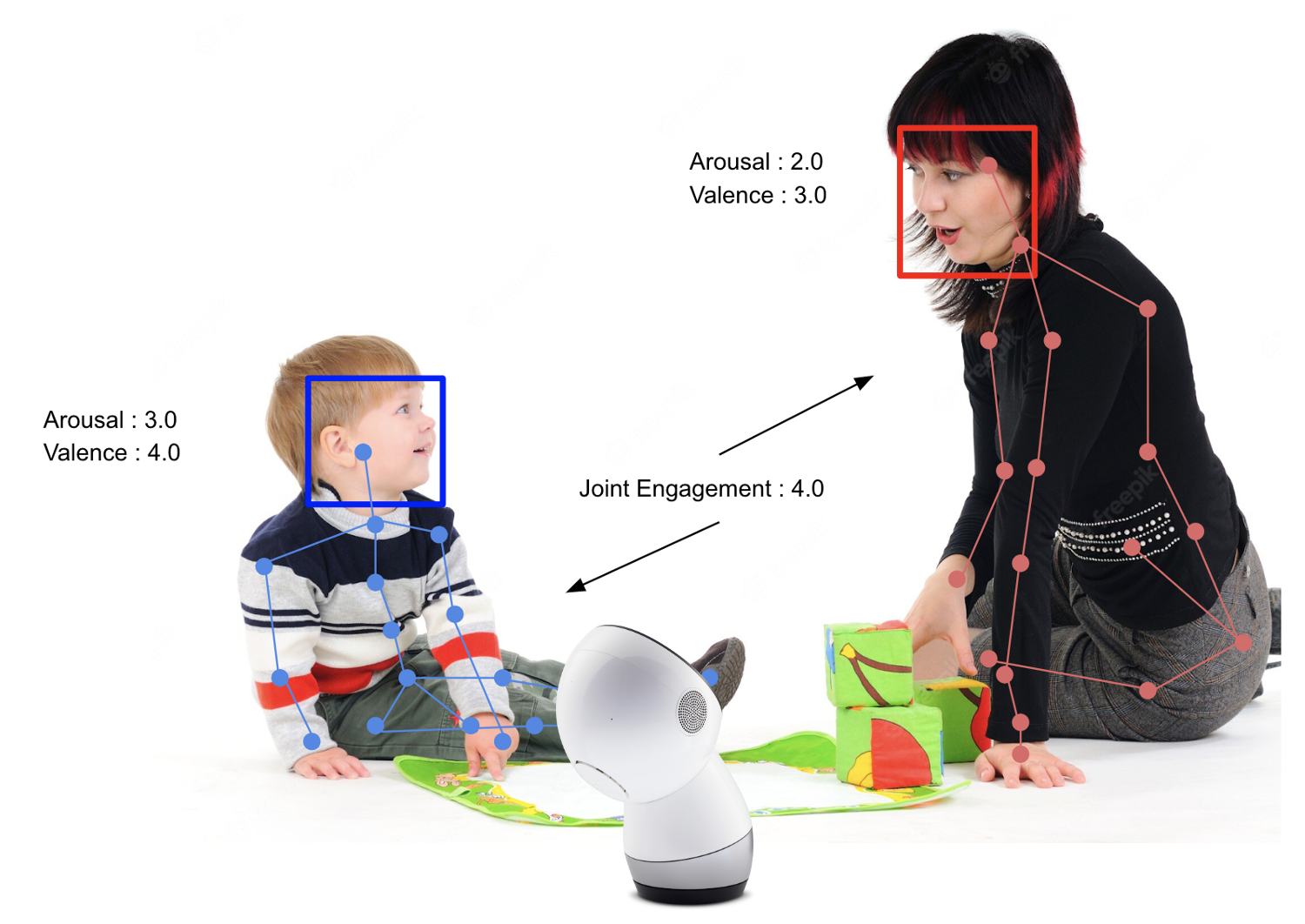
A social robot was deployed and teleoperated remotely in the homes of 12 families with 3-7-year-old children to engage in a triadic story-reading activity with the parent and child over the course of six 25-minute sessions and 3 to 6 weeks in total. For each triadic session, audiovisual recordings were captured and subsequently used to annotate the quality of parent-child engagement. We chose the Joint Engagement Rating Inventory (JERI) [1] to measure parent-child engagement, as it has been utilized and validated in previous parent-child interaction studies [1, 4].
Using the intra-class correlation (ICC) type (3,1) for average fixed raters, the agreement among the three annotators was measured. Given these evaluation criteria, the annotation quality with ICC=0.95 exceeded the threshold for very good quality (0.75 ≤ 𝐼𝐶𝐶 ≤ 1.0). After recordings were independently coded by the annotators, the final score for each recording fragment was determined by averaging the ratings assigned to each scale by the two annotators. We convert the 5-scale into three classification levels (Low: 8.49%, Medium: 49.68%, and High: 41.83%) for model training and testing. Strictly following the annotation protocol in [4], we annotated 16,606 five-second video clips with 1517.08 ± 309.34 fragments from each family on average.
Video Augmentation
General Aug This technique is applied to diversify the background (replace the background with RGB color, random indoor image, and blur the background), encouraging the model’s robust learning by adding noise to the whole frame, randomly rotating an image, applying horizontal flipping, and lastly, giving hints of semantics in the frame by applying semantic segmentations. DeepFake DeepFake was applied for dyads’ faces to overcome the small populations in the original dataset and also for debiasing purposes. We used SimSwap [8] for multi-person face swapping in videos. To feed a diverse set of target face images, we also utilized AI-generated face dataset (https://generated.photos/faces) which supports realistic customizations (e.g., race, gender, age, accessories, and hair type). Mixed We also wanted to see if combining the datasets that showed performance improvement individually would make even more performance improvements once combined. To do this, we randomly sampled video clips from both General Aug and DeepFake while keeping the same ratio from each dataset. CutOut CutOut is a well-known but simple regularization technique that randomly masks out square regions of input during training (spatial prior dropout in input space). This can be used to improve the robustness and overall performance when conducting classification tasks, and in this work, CutOut is used to validate the model’s representation learning without the core information in the scenes (i.e. face).
Methods
1. RGB frame-based models
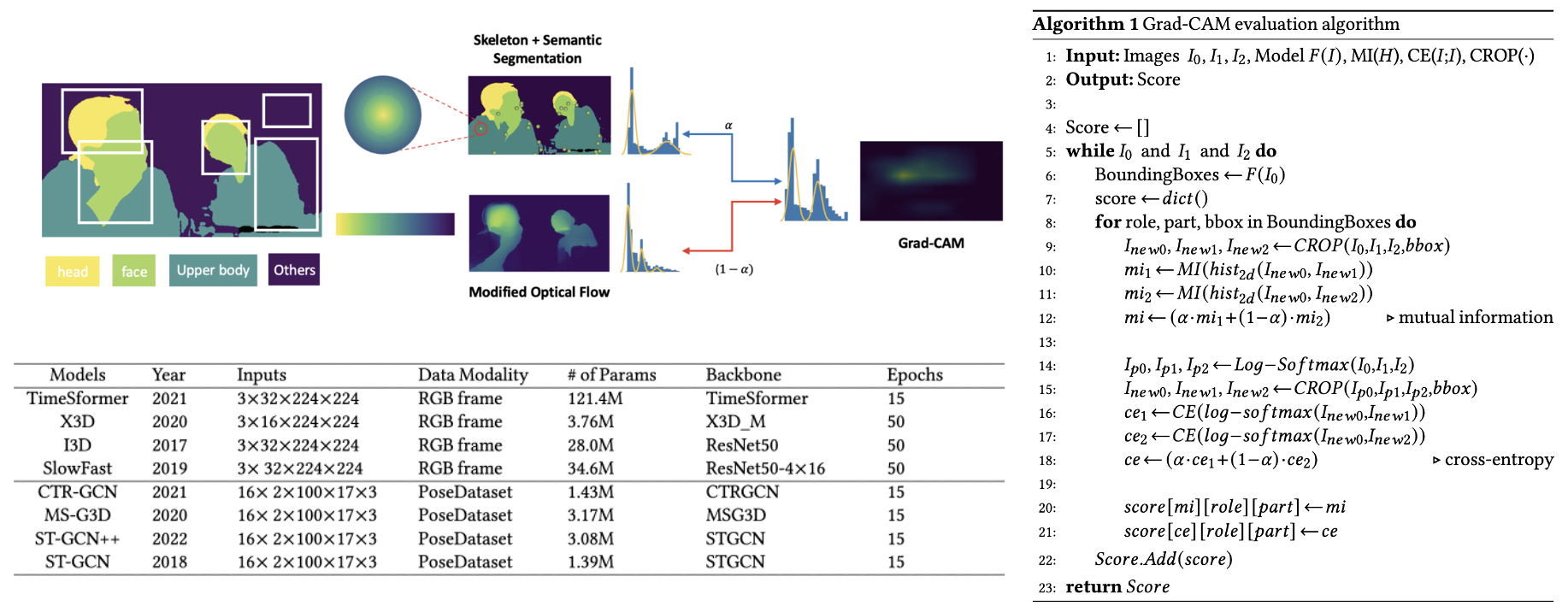
1-1) TimeSformer is only built on self-attention over space and time. It adapts the Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. 1-2) X3D is a family of efficient video networks that continuously expand a small 2D image classification architecture along multiple network axes (space, time, width, and depth). 1-3) I3D is a 2D ConvNet inflation-based model, in which the filters and pooling kernels of deep image classification ConvNets are expanded into 3D. 1-4) SlowFast proposes a dual-pathway structure to combine the benefits of a slow pathway for static spatial features and a fast pathway for dynamic motion features
2. Skeleton-based models
2-1) CTR-GCN proposes Channel-wise Topology Refinement Graph Convolution Network dynamically learns different topologies and effectively aggregates joint features in different channels. 2-2) MS-G3D (multi-Scale aggregation Scheme) disentangles the importance of nodes in different neighborhoods for effective long-range modeling. 2-3) ST-GCN & ST-GCN++ adopts Graph Convolution Neural (GCN) Networks for skeleton processing.
3. Image-matching metrics
First, we adopt mutual information, a dimensionless quantity metric that measures the mutual dependence between two variables. The metric is high when the attention map signal is highly concentrated in a few histogram bins, and low when the signal is spread across many bins. Here, we convert the image into a distribution by flattening the image arrays and then compute the bi-dimensional histogram of two image array samples. The second metric is cross-entropy, which comes from the Kullback-Leibler divergence. This is a widely used metric for calculating the difference between two distributions. Here, we first normalize the pixel values in images and then pass this through log-softmax to convert images into distributions. Then we apply cross-entropy. Given that we have all the bounding boxes for each parent’s and child’s face and body, we could separate these values based on their bounding box coordinates.
Experiments
We conduct experiments to evaluate the effectiveness of the proposed video augmentation techniques; General Aug, DeepFake, Mixed, and CutOut to see their capability to improve joint engagement recognition on state-of-the-art action recognition models. Also, we compare the joint engagement classification performance between RGB frame-based and skeleton-based models to see the effect of different inputs in this task. For the implementation, we utilized MMAction2 and Pyskl, an open-source toolbox for video understanding based on PyTorch and all of the models were trained on 8 NVIDIA 1080Ti GPUs.
Visualization
Grad-CAM inference video
</video>
Conclusion
The performance and visualization of the state-of-the-art end-to-end video classification models for recognizing joint engagement demonstrated their potential to recognize complex human-human joint affective states with limited training data. The fine-tuned end-to-end models initially pre-trained for general video understanding (e.g., SlowFast, I3D) performed more effectively on joint engagement recognition than the models trained on human skeleton features (e.g., CTR-GCN, ST-GCN). The video augmentation techniques enhanced the model’s performance even further. The visualization of the learned representations in the end-to-end deep learning models revealed their sensitivity to subtle social cues indicative of parent-child interaction. Altogether, these findings and insights indicate that end-to-end models were able to learn the representation of parent-child joint engagement in an interpretable manner.
In the future work, we are interested in providing answers to the following discussion points :
1. Personalization Our proposed framework can also be expanded to account for individual differences in affect across dyads by adding a deep neural network layer as the final layer trained on individual human groups
2. Multi-modal representation learning Extend the model learning from a single video-based to multi-modal (e.g., audio, video, text and skeleton) learning and compare the learned representation
3. Comparison of Video Augmentation techniques Apply various type (temporal, spatial, etc) of video augmentation techniques and evaluate, compare the results to demonstrate its effectiveness