Health-LLM: Large Language Models for Health Prediction via Wearable Sensor Data
Abstract
Large language models (LLMs) are capable of many natural language tasks, yet they are far from perfect. In health applications, grounding and interpreting domain-specific and non-linguistic data is important. This paper investigates the capacity of LLMs to make inferences about health based on contextual information (e.g. user demographics, health knowledge) and physiological data (e.g. resting heart rate, sleep minutes). We present a comprehensive evaluation of 12 publicly accessible state-of-the-art LLMs with prompting and fine-tuning techniques on four public health datasets (PMData, LifeSnaps, GLOBEM and AW_FB). Our experiments cover 10 consumer health prediction tasks in mental health, activity, metabolic, and sleep assessment. Our fine-tuned model, HealthAlpaca exhibits comparable performance to much larger models (GPT-3.5, GPT-4 and Gemini-Pro), achieving the best or second best performance in 7 out of 10 tasks. Ablation studies highlight the effectiveness of context enhancement strategies. Notably, we observe that our context enhancement can yield up to 23.8% improvement in performance. While constructing contextually rich prompts (combining user context, health knowledge and temporal information) exhibits synergistic improvement, the inclusion of health knowledge context in prompts significantly enhances overall performance.
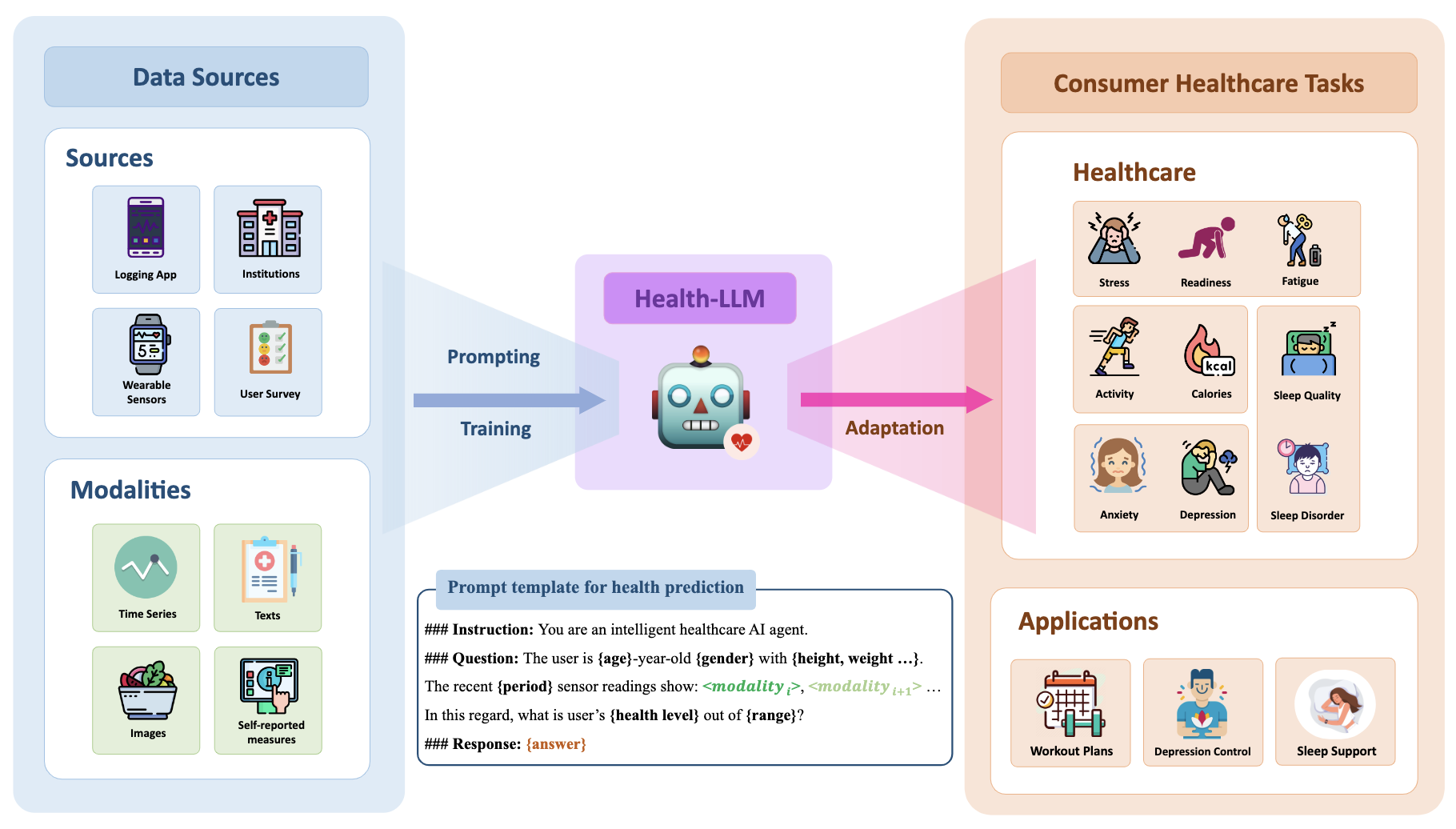
Health-LLM: We presents a framework for evaluating LLM performance on a diverse set of health prediction tasks, training and prompting the models with multi-modal health data.
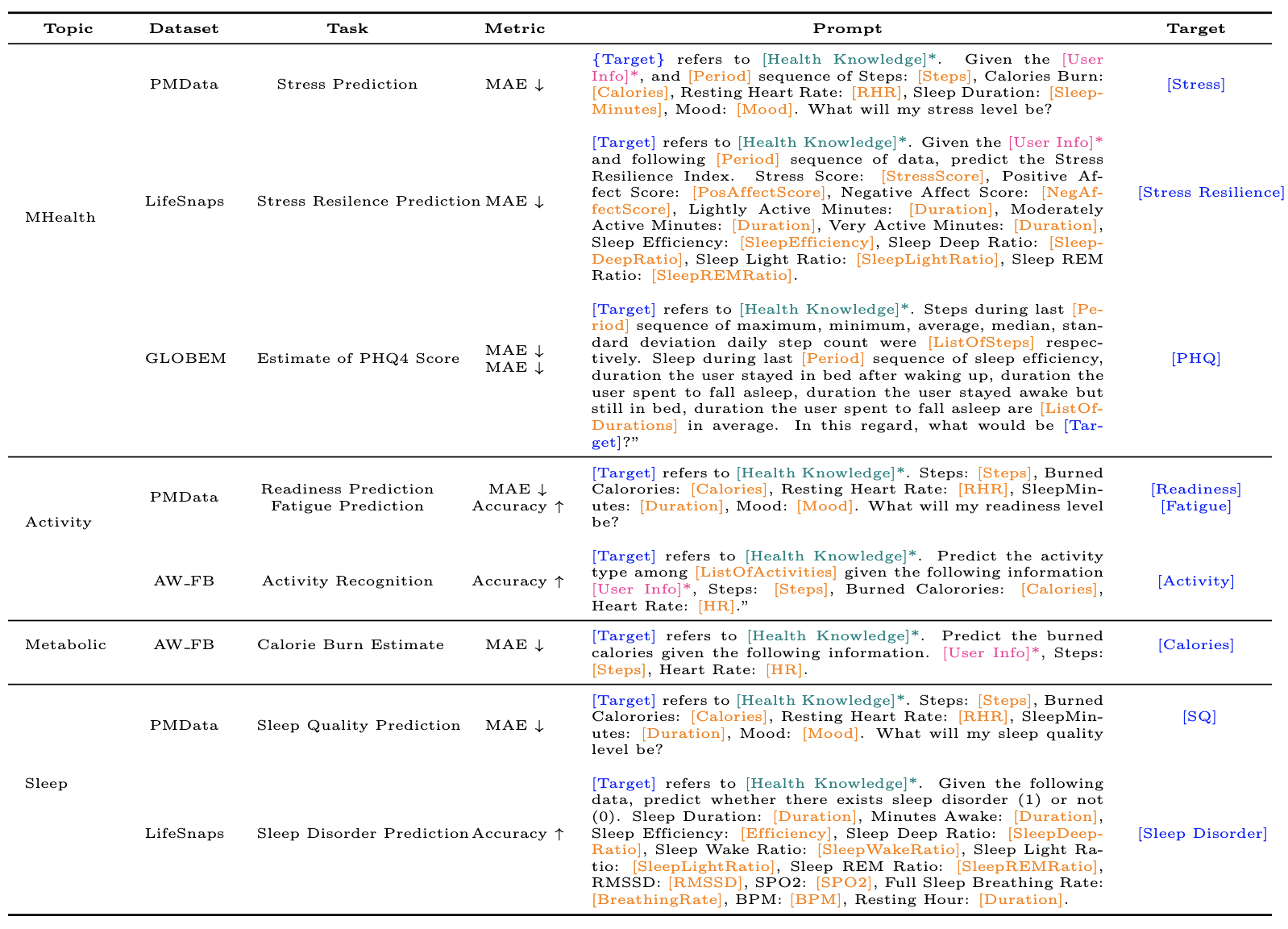
Consumer Health Tasks We define ten tasks from four datasets and classify them into five topics. * in the prompt indicates the optional contexts for the ablation
We consider four wearable sensor datasets that contained: (1) multi-modal physiological data, (2) user self-reported measures, (3) enough distinct time windows to evaluate over. This table summarizes the dataset topic, tasks, metric to evaluate, size and text length presents the features used in the prompt for each task. For the train/test split, we selected 0.1 portion of the original set as the test set and randomly sampled the data from different participants as possible. The choice of ten tasks across four datasets were inspired by the functions provided by consumer health wearables (e.g. Fitbit, Apple Watch) and the previous works of LLMs in diverse applications

We introduce a comprehensive zero-shot prompting along with four types of context enhancements introduced in the table above and equations
1) User Context (uc) provides user-specific information such as age, gender, weight, height, etc., which provides additional information that affects the understanding of health knowledge.
2) Health Context (hc) provides the definition and equation that controls certain health targets to inject new health knowledge into LLMs.
3) Temporal Context (tc) is adopted to test the importance of temporal aspects in time-series data. Instead of using aggregated statistics, we utilize the raw time-series sequence. Among different sets of temporal context representations, we empirically observe that using natural language string showed the best performance.
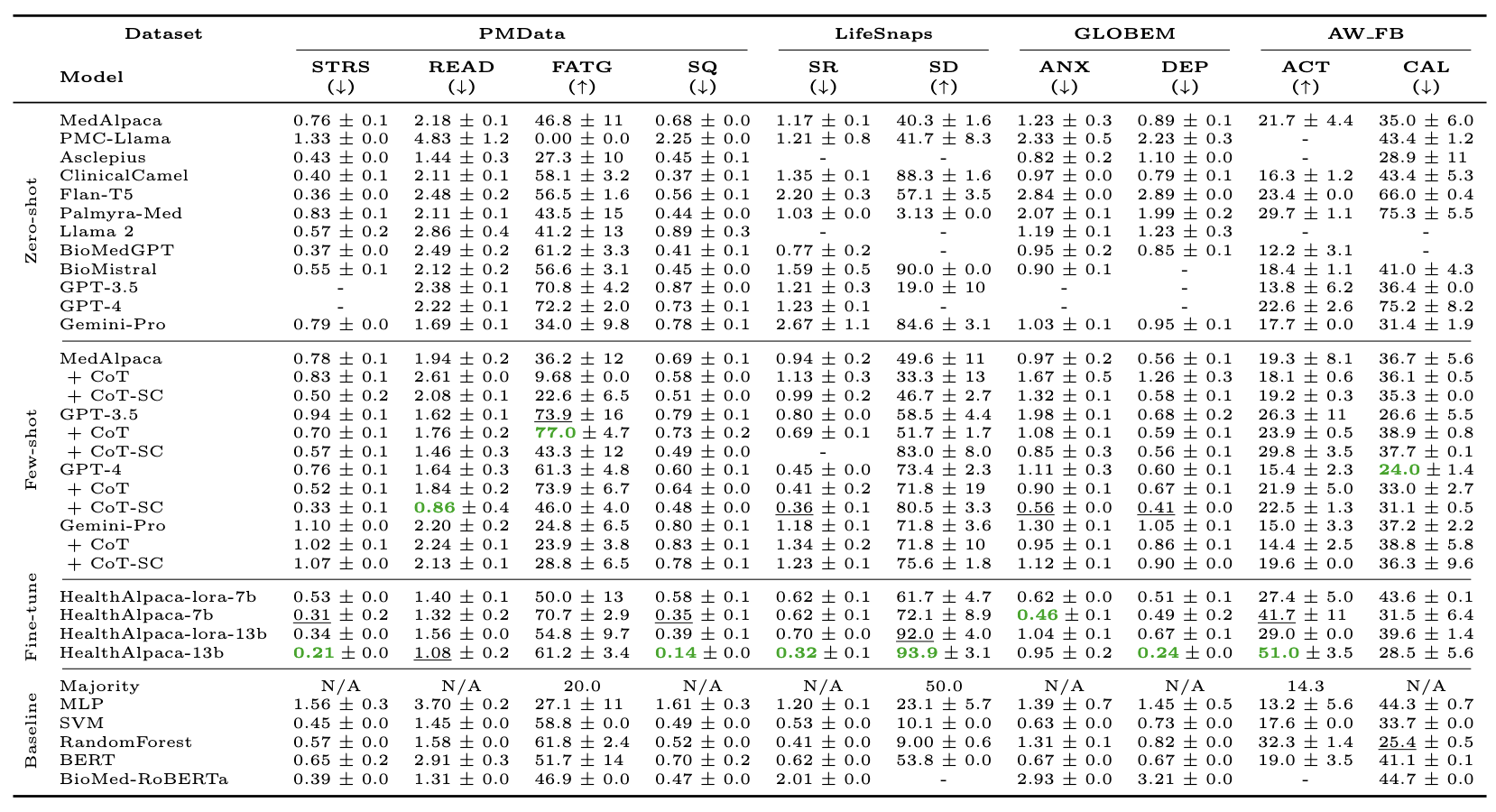
Performance Evaluation of LLMs on Health Prediction Tasks STRS: Stress, READ: Readiness, FATG: Fatigue, SQ: Sleep Quality, SR: Stress Resilience, SD: Sleep Disorder, ANX: Anxiety, DEP: Depression, ACT: Activity, CAL: Calories. “-” denotes the failure cases due to token size limit or unreasonable responses. “N/A” denotes the case where the prediction is not reported or cannot be conducted. For each column (task), the best result is bolded, and the second best is underlined. CoT denotes the chain-of-thoughts and SC denotes the self-consistency prompting. For each task, arrows in the parenthesis indicate the desired direction of improvement. ↑ indicates higher values are better for accuracy, while ↓ indicates lower values are better for mean absolute error.
In this paper, we present the first comprehensive evaluation of off-the-shelf LLMs, including MedAlpaca, PMC-Llama, Asclepius, ClinicalCamel, FLAN-T5, Palmyra-Med, Llama 2, BioMedGPT, BioMistral, GPT-series models, and Gemini-Pro, across ten consumer health prediction tasks (binary, multi-class classification, and regression) spanning four public health datasets. Our experiments encompass a variety of prompting and fine-tuning techniques. The results reveal several interesting findings. First, our context enhancement strategy significantly improves performance across all datasets and LLMs, particularly emphasizing the importance of incorporating health knowledge context in prompts. More importantly, our fine-tuned model, HealthAlpaca, demonstrates the best or second-best performance in 7 out of 10 tasks, outperforming much larger models such as GPT-3.5, GPT-4, and Gemini-Pro, even when these are equipped with few-shot prompting. Additionally, we conducted a case study on selected examples to highlight the LLMs' reasoning capabilities and limitations regarding false and hallucinated reasoning in health predictions. However, ethical concerns regarding privacy and bias remain, necessitating further investigation before real-world deployment.
This study's reliance on self-reported health data limits its clinical applicability and raises ethical considerations, particularly regarding data validity and user communication. Additionally, the "black-box" nature of LLMs complicates the assessment of their clinical validity. To address these issues, future work will focus on:
1) conducting evaluations with clinically diagnosed datasets in collaboration with healthcare professionals to enhance clinical relevance
2) ensuring ethical and regulatory compliance, particularly in how health-related predictions are communicated to users
3) improving LLMs' explainability to facilitate understanding of their decision-making processes, thereby aiding in the accurate interpretation of health predictions
4) incorporating privacy-preserving technologies like federated learning to protect sensitive health information.
Keywords
Overview
Health-LLM: We presents a framework for evaluating LLM performance on a diverse set of health prediction tasks, training and prompting the models with multi-modal health data.
Dataset & Tasks
Consumer Health Tasks We define ten tasks from four datasets and classify them into five topics. * in the prompt indicates the optional contexts for the ablation
We consider four wearable sensor datasets that contained: (1) multi-modal physiological data, (2) user self-reported measures, (3) enough distinct time windows to evaluate over. This table summarizes the dataset topic, tasks, metric to evaluate, size and text length presents the features used in the prompt for each task. For the train/test split, we selected 0.1 portion of the original set as the test set and randomly sampled the data from different participants as possible. The choice of ten tasks across four datasets were inspired by the functions provided by consumer health wearables (e.g. Fitbit, Apple Watch) and the previous works of LLMs in diverse applications
Context Enhancement
We introduce a comprehensive zero-shot prompting along with four types of context enhancements introduced in the table above and equations
1) User Context (uc) provides user-specific information such as age, gender, weight, height, etc., which provides additional information that affects the understanding of health knowledge.
2) Health Context (hc) provides the definition and equation that controls certain health targets to inject new health knowledge into LLMs.
3) Temporal Context (tc) is adopted to test the importance of temporal aspects in time-series data. Instead of using aggregated statistics, we utilize the raw time-series sequence. Among different sets of temporal context representations, we empirically observe that using natural language string showed the best performance.
Experiments
Performance Evaluation of LLMs on Health Prediction Tasks STRS: Stress, READ: Readiness, FATG: Fatigue, SQ: Sleep Quality, SR: Stress Resilience, SD: Sleep Disorder, ANX: Anxiety, DEP: Depression, ACT: Activity, CAL: Calories. “-” denotes the failure cases due to token size limit or unreasonable responses. “N/A” denotes the case where the prediction is not reported or cannot be conducted. For each column (task), the best result is bolded, and the second best is underlined. CoT denotes the chain-of-thoughts and SC denotes the self-consistency prompting. For each task, arrows in the parenthesis indicate the desired direction of improvement. ↑ indicates higher values are better for accuracy, while ↓ indicates lower values are better for mean absolute error.
Conclusion
In this paper, we present the first comprehensive evaluation of off-the-shelf LLMs, including MedAlpaca, PMC-Llama, Asclepius, ClinicalCamel, FLAN-T5, Palmyra-Med, Llama 2, BioMedGPT, BioMistral, GPT-series models, and Gemini-Pro, across ten consumer health prediction tasks (binary, multi-class classification, and regression) spanning four public health datasets. Our experiments encompass a variety of prompting and fine-tuning techniques. The results reveal several interesting findings. First, our context enhancement strategy significantly improves performance across all datasets and LLMs, particularly emphasizing the importance of incorporating health knowledge context in prompts. More importantly, our fine-tuned model, HealthAlpaca, demonstrates the best or second-best performance in 7 out of 10 tasks, outperforming much larger models such as GPT-3.5, GPT-4, and Gemini-Pro, even when these are equipped with few-shot prompting. Additionally, we conducted a case study on selected examples to highlight the LLMs' reasoning capabilities and limitations regarding false and hallucinated reasoning in health predictions. However, ethical concerns regarding privacy and bias remain, necessitating further investigation before real-world deployment.
Limitations and Future Works
This study's reliance on self-reported health data limits its clinical applicability and raises ethical considerations, particularly regarding data validity and user communication. Additionally, the "black-box" nature of LLMs complicates the assessment of their clinical validity. To address these issues, future work will focus on:
1) conducting evaluations with clinically diagnosed datasets in collaboration with healthcare professionals to enhance clinical relevance
2) ensuring ethical and regulatory compliance, particularly in how health-related predictions are communicated to users
3) improving LLMs' explainability to facilitate understanding of their decision-making processes, thereby aiding in the accurate interpretation of health predictions
4) incorporating privacy-preserving technologies like federated learning to protect sensitive health information.
Publication