Training Self-Driving Car using DDPG Algorithm
Training Self-Driving Car using Deep Deterministic Policy Gradient (DDPG) Algorithm
Research Topics
Overview
Deep Reinforcement Learning (DRL) based algorithms have been recently used to solve Markov Decision Processes (MDPs), where the scope of the algorithm is to calculate the optimal policy of an agent to choose actions in an environment with the goal of maximize a reward function, obtaining quite successful results in fields like solving computer games or simple decision-making system [1].
The discrete nature of DQN is not well studied ongoing problem like self-driving, due to the infinite possibles of movement the car in each step. Studying DQN and the obtained results, we will analyze the limitations of this method for this navigation purpose. On the other hand, the DDPG algorithm has a continuous nature that fits better to autonomous driving task.
In this work, we implement DDPG algorithm to train an agent in V-REP (nowadays called Coppelia Sim) simulator which involves physics engine and evaluate the performance of trained self-driving car.
The discrete nature of DQN is not well studied ongoing problem like self-driving, due to the infinite possibles of movement the car in each step. Studying DQN and the obtained results, we will analyze the limitations of this method for this navigation purpose. On the other hand, the DDPG algorithm has a continuous nature that fits better to autonomous driving task.
In this work, we implement DDPG algorithm to train an agent in V-REP (nowadays called Coppelia Sim) simulator which involves physics engine and evaluate the performance of trained self-driving car.
Methods

To control the simulated vehicle, we used Ackermann Steering and we defined 2-dimensional action space where action[0] is the speed and action[1] is the steering angle. For observation space, we defined it on 27-dimensional space where 24-dimensions are the LiDAR array and the rest four are relative angle towards the center road line, v_x and v_y. We had many trial and error and defined the reward function as below:
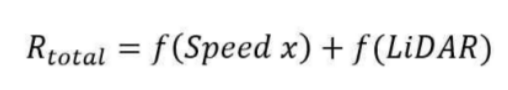
(where f(speed_x) is the magnitude of speed in x-direction according to the center road line and f(LiDAR) is sum of lidar rewards on front, side, and back which are defined with the empirical thresholds)
To prevent from getting overfitted, we randomly positioned an agent in random positions and random direction angles (In the later work, we also generated random tracks for each iteraction).
(where f(speed_x) is the magnitude of speed in x-direction according to the center road line and f(LiDAR) is sum of lidar rewards on front, side, and back which are defined with the empirical thresholds)
To prevent from getting overfitted, we randomly positioned an agent in random positions and random direction angles (In the later work, we also generated random tracks for each iteraction).
Experiment and Result

In this work, since the simulator involved high-quality physics engine, it took few days to train an agent and due to this reason, we disabled the graphics during the training.
Every episode was terminated whenever the vehicle 1) collides with the environment, 2) go backward direction. For the first 50 episodes, agent showed totally random movements, but after 200 episodes, the agent started to behave well and show reasonable performance. Exploration was also an important factor when training an agent. In DDPG, we utilize Ornstein-Ulenbeck(OU) noise and add this to the output action (I empirically controlled this value within the boundary from -0.3 to 0.3).
Future work should involve more realistic environment with multiple agents at a same time.
Every episode was terminated whenever the vehicle 1) collides with the environment, 2) go backward direction. For the first 50 episodes, agent showed totally random movements, but after 200 episodes, the agent started to behave well and show reasonable performance. Exploration was also an important factor when training an agent. In DDPG, we utilize Ornstein-Ulenbeck(OU) noise and add this to the output action (I empirically controlled this value within the boundary from -0.3 to 0.3).
Future work should involve more realistic environment with multiple agents at a same time.
References
[1] Pérez-Gil, Ó., Barea, R., López-Guillén, E., Bergasa, L. M., Gómez-Huélamo, C., Gutiérrez, R., & Díaz-Díaz, A. (2022). Deep reinforcement learning based control for autonomous vehicles in carla. Multimedia Tools and Applications, 81(3), 3553-3576.
[2] https://github.com/Hong123123/DDPG_VREP
[3] Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., ... & Wierstra, D. (2015). Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971.